


Valid Anagram
by Utkarsh Jaiswal
Technology
March 29, 2024
|
6 min read
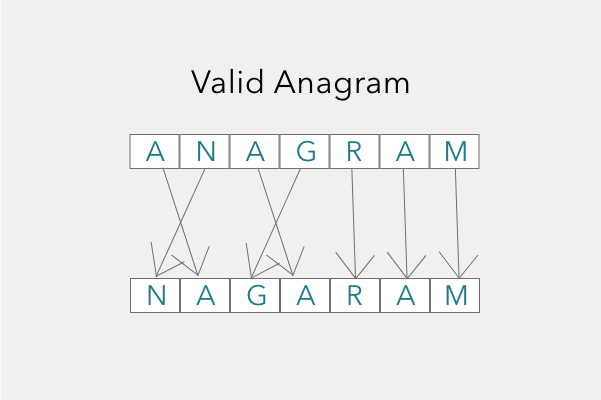
In this blog post, we'll tackle the classic LeetCode problem (242) of identifying valid anagrams. Anagrams are words or phrases formed by rearranging the letters of another word. For example, "cinema" and "ice man" are anagrams. Given two strings s and t, we need to determine if they are anagrams.
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram" Output: true
Example 2:
Input: s = "rat", t = "car" Output: false
Constraints:
1 <= s.length, t.length <= 5 * 104sandtconsist of lowercase English letters.
Brute Force Approach
The brute force method involves sorting both strings and comparing them. If the sorted strings are equal, we can conclude that they are valid anagrams.
function isAnagram(s, t) {
return s.split('').sort().join('') === t.split('').sort().join('');
}
Explanation:
- We convert both
sandtto arrays of characters usingsplit(''). - We sort the character arrays using
sort(). This rearranges the characters in alphabetical order. - We convert the sorted arrays back to strings using
join(''). - Finally, we compare the sorted strings with
===.
- Time Complexity: O(n log n) - Sorting dominates here, leading to O(n log n) time complexity, where
nis the length of the strings. - Space Complexity: O(1) - We use built-in methods without creating additional data structures, resulting in O(1) space complexity.
Optimized Approach
While sorting works, it can be inefficient for large strings.The optimized approach utilizes a hashmap-like object to store the frequency of characters in one string and then checks if the second string matches the frequency of characters in the hashmap, Here's the improved code:
function isAnagram(s, t) {
if (s.length !== t.length) {
return false; // Different lengths cannot be anagrams
}
const charCount = {};
for (const char of s) {
charCount[char] = (charCount[char] || 0) + 1; // Increment count for characters in s
}
for (const char of t) {
if (!charCount[char] || charCount[char] === 0) {
return false; // Missing characters in t
}
charCount[char]--; // Decrement count for characters in t
}
return true; // All characters matched
}
Explanation:
- We check if the lengths of
sandtare different. If so, they cannot be anagrams, and we returnfalse. - We create an object
charCountto store frequency counts of characters ins. - We iterate through each character
charins:
- If
charexists incharCount, we increment its count by 1. - Otherwise, we initialize
charCount[char]to 1.
- We iterate through each character
charint:
- If
chardoesn't exist incharCountor its count is 0, it means thatthas characters missing froms. We returnfalse. - Otherwise, we decrement
charCount[char].
- If we reach this point, it means all characters from
thave matching frequencies ins. We returntrue.
- Time Complexity: O(n) - We iterate through both strings once, leading to O(n) time complexity.
- Space Complexity: O(n) - We create the
charCountobject to store frequency counts, resulting in O(n) space complexity.